Hyunjung Im
Frontend Developer

Sort
2022-05-07
Sorting 알고리즘
- 왜 정렬 알고리즘을 배워야 할까?
- 정렬 알고리즘은 어떨 때 쓰이나?
- In Place
- Stable (안정)
- Bubble sort
- Bubble Sort 시간복잡도
- Insertion Sort 삽입 정렬
- 시간복잡도
- What is Stable?
- Quick Sort
- 시간복잡도
- Merge Sort
- 시간 복잡도
왜 정렬 알고리즘을 배워야 할까?
정렬 알고리즘은 거의 처음으로 생겨난 알고리즘. 즉 정렬은 프로그래밍을 할 때 꼭 필요한 기능이고 정렬이라는 결과를 만드는 방법이 아주 다양하다는 의미입니다.
“classic” 정렬 알고리즘은 매우 간단하므로 알고리즘을 공부하기 위한 훌륭한 출발점이다. 동일한 작업(정렬)에 사용할 수 있는 다양한 알고리즘을 연구하여 worst-case time complexity, average-case time complexity, worst-case extra space, average-case extra space 를 분석하는 방법을 공부할 수 있다.
- 알고리즘을 이해하고 쓰는 것과 주어져 있는 메소드만 쓸 수 있는 것에는 많은 차이를 가져올 수 있습니다.
- 정렬 알고리즘을 이해해야지 쓸 수 있는 도구들이 늘어나게 됩니다.
- 더 개선된 퍼포먼스를 위해
- 레코드가 많을 때 (큰 데이터를 기준으로 정렬할 때)
- 작은 레코드 (메서드를 쓰기에 레코드가 작아서 리소스가 낭비될 수도 있기 때문)
- stable 정렬 알고리즘이 스테이블한가 언스테이블한가 (중복데이터의 순서가 sort했을 때 유지된다면 stable, 순서가 유지되지 않으면 unstable)
정렬 알고리즘은 어떨 때 쓰이나?
- 사람들 리스트 정렬
- 중간값 구할 때
- 중복값 찾을 때
- 이진 탐색 트리 BST (정렬이 되어있을 때를 전제하기 때문에)
In Place
In Place라는 의미는 원소들을 정렬하는 과정에서 추가적인 공간을 필요로 하지 않고, 이미 할당된 공간 내에서 자리를 바꾸어가며 원소들을 정렬 한다는 의미
- 추가적인 공간이 필요없는 것
- 주어진 공간 외에는 메모리를 쓸 필요 없음.
- 쓰기 쉽다. 비기너에게 좋다. (이해하기 쉽다)
- 정렬이 되어있는지 판별할 때 적절할 수 있다.
Stable (안정)
정렬 알고리즘에서 Stable은 정렬되지 않은 원소들끼리 정렬 이전과 동일한 상대적인 위치를 그대로 유지한다는 의미. 즉 정렬을 했을 때 중복된 값들의 순서가 정렬 이전과 동일하다면 Stable한 정렬입니다.
대표적인 Stable Sorting 알고리즘의 종류
- Bubble Sort
- Insertion Sort
- Merge Sort
- Counting Sort
Bubble sort
거품 정렬 또는 버블 정렬(bubble sort, sinking sort)라고 하고 두 인접한 원소를 검사하여 정렬하는 방법. 시간 복잡도가 O(n^2)로 상당히 느리지만, 코드가 단순하기 때문에 자주 사용됩니다. 원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 때문에 지어진 이름. 양방향으로 번갈아 수행되면 칵테일 정렬이 됩니다.

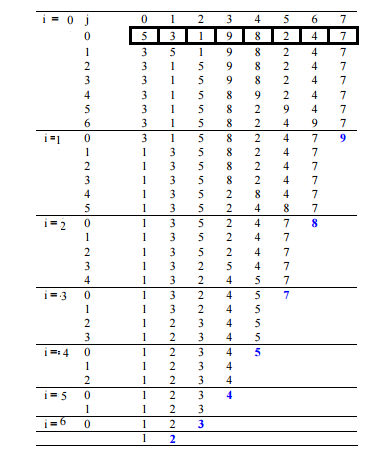
의사코드로 나타낸 알고리즘
procedure bubbleSort( A : list of sortable items ) defined as:
for each i in 1 to length(A) do:
for each j in length(A) downto i + 1 do:
if A[ j ] < A[ j - 1 ] then
swap( A[ j ], A[ j - 1 ] )
end if
end for
end for
end procedure28 24 27 18
- 첫 순회 1-1. 첫 번째, 두 번째 비교 왼쪽께 크면 오른쪽으로 버블링 (올린다) - 24 28 27 18 1-2. 28, 27비교 -> 28을 오른쪽으로 버블링 - 24 27 28 18 1-3. 순회 끝 - 결과 : 24 27 18 28 (n(1)번 순회하면 오른쪽의 n(1)만큼이 정렬된다.)
- 두 번째 순회
- 결과 : 24 18 27 28 (n(2)번 순회하면 오른쪽의 n(2)만큼이 정렬된다.)
- 세 번째 순회
- 결과 : 18 24 27 28 (n(3)번 순회하면 오른쪽의 n(3)만큼이 정렬된다.)
한 번 순회할 때 왼쪽에서 오른쪽으로 두 가지 숫자를 비교하고 큰 수를 오른쪽으로 버블링 되는 것처럼 옮겨간다.
규칙 : 만약에 k번 순회 한다고 했을 때 오른쪽에서 부터 k 만큼의 요소들이 정렬이 된다
Bubble Sort 시간복잡도
한 번 순회 : O(n)
순회(n)를 n번 반복 -> O(n^2)
Worse Case : O(n^2)
- 배열의 요소가 내림차순으로 정렬될 때 발생한다.
Best Case : O(n)
- 가장 좋은 경우는 배열이 이미 정렬되어 있을 때 발생한다.
Auxiliary Space : O(1)
- (보조 공간: 알고리즘이 문제를 해결하기 위해 임시로 사용하는 공간)
Sorting In Place : Yes
Stable : Yes
장점
- 버블 소트는 “in place” 알고리즘입니다.
단점
데이터가 크면 클수록 느려집니다.
Selection Sort 선택 정렬
- In Place 정렬
- 첫 번째 순서에서는 가장 최솟값을 넣는다.
- 두 번째 순서에서는 남은 값 중에서 최솟값을 넣는다.

Special Sort (버블 정렬 응용)
Insertion Sort 삽입 정렬
자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘입니다.
이는 quicksort, heapsort, merge sort와 같은 고급 알고리즘보다 큰 리스트를 다루게 될 땐 훨씬 덜 효율적.
왼쪽으로 오른쪽으로 순회하면서 각 요소를 집어넣습니다. (적절한 위치에)
기존 원소의 왼쪽 에 있는 원소들과 하나씩 비교하여 자리를 찾아가는 과정을 반복하여 데이터를 정렬
- 두 번째 요소부터 시작 (왼쪽과 비교해야해서)
- 이진 검색을 사용하여 일반 삽입 정렬에서 비교 횟수를 줄일 수 있습니다.
- 이진 삽입 정렬은 이진 검색을 사용하여 각 반복에서 선택한 항목을 삽입할 적절한 위치를 찾습니다.
- 정상적인 삽입에서 정렬은 최악의 경우 O(i)(i번째 반복)을 취합니다. 이진 검색을 사용하여 O(logi)로 줄일 수 있어요. 알고리즘은 전체적으로 각 삽입에 필요한 일련의 스왑으로 인해 여전히 최악의 실행 시간이 O(n^2)입니다. link
Binary Insertion Sort 이진 삽입 정렬


의사코드로 나타낸 알고리즘
i ← 1
while i < length(A)
j ← i
while j > 0 and A[j-1] > A[j]
swap A[j] and A[j-1]
j ← j - 1
end while
i ← i + 1
end while시간복잡도
- Worst Case: O(n^2)
- 역순으로 정렬되어있는 경우 최악의 시간복잡도를 가집니다.
- Best Case: O(n)
- 요소가 이미 정렬되어 있는 경우
- Sorting In Place : Yes
- Stable : Yes
장점
- 버블과 유사 insert도 in-place 알고리즘
- 복잡한 규칙이 없어서 어렵지 않음.
- 요소가 적을 때 사용하면 좋음. 큰 배열이지만 거의 정렬되어있고 소수의 요소만 잘못 배치된 경우에 유용할 수 있음.
단점
- 버블과 마찬가지로 데이터 커질수록 속도가 느려짐
What is Stable?
Quick Sort
pivot (기준)을 하나 고른 후, 피벗값보다 작은 원소들을 왼쪽으로 보내고 큰 원소들은 오른쪽으로 보내며 원소들을 다른 파트로 나누어 갑니다.(Partitioning)
- 피벗 뽑기
- 왼쪽에 작은 애들 오른쪽에 큰 애들 이렇게 배열 정리
- 왼쪽에서도 또 피벗 뽑아서 같은 작업
- 오른쪽에도 반복
시간복잡도
Worst Case: O(n^2) (매번 피벗을 가장 큰 값으로 골랐을 떄) Best Case: O(n log n)
단점
- Unstable 하다
- 피벗에 따라 영향을 많이 받습니다. (해시테이블 단점: 해시펑션 의존도 큼)
- 이미 정렬된 리스트에는 부적절할 수 있습니다.
장점
- 기본적으로 효율성이 좋습니다.
- 생각보다 쓰는 게 어렵지 않음(…)
- In Place로 구현할 수 있습니다.
Merge Sort
merge: 통합하다. 하나의 데이터 리스트를 여러 개로 나누고 다시 병합하며 작은 단위의 정렬을 반복하여 전체의 정렬을 이루어 내는 방식의 정렬 알고리즘
시간 복잡도
Worst Case: O(n log n) (잘라서 바이너리로 들어가는 건 다 log n) Best Case: O(N log n)
추가 공간이 필요함. 공간 복잡도 : O(n)space
장점
- 항상 시간복잡도가 일정 : 성능에 대한 예측이 가능함.
Divide and Conquer
- Divide: 내가 가진 문제를 반으로 쪼갠다.
- Conquer: 서브 문제를 해결한다.
- Combine: 쪼개진 걸 통합한다.